




What 170 million documents reveal about amateur and professional document fraud
Document fraud has changed. What used to be a craft practiced by skilled forgers has industrialized into a supply chain serving everyone from first-time opportunists to organized crime rings.
After analyzing 170 million+ documents, it’s very clear: the line between amateur and professional fraud is blurring (and both sides are getting better).
This report examines the state of document fraud in 2025 and what it means for 2026. We'll cover the threats, where they concentrate, and why detection alone isn't enough.
Key statistics
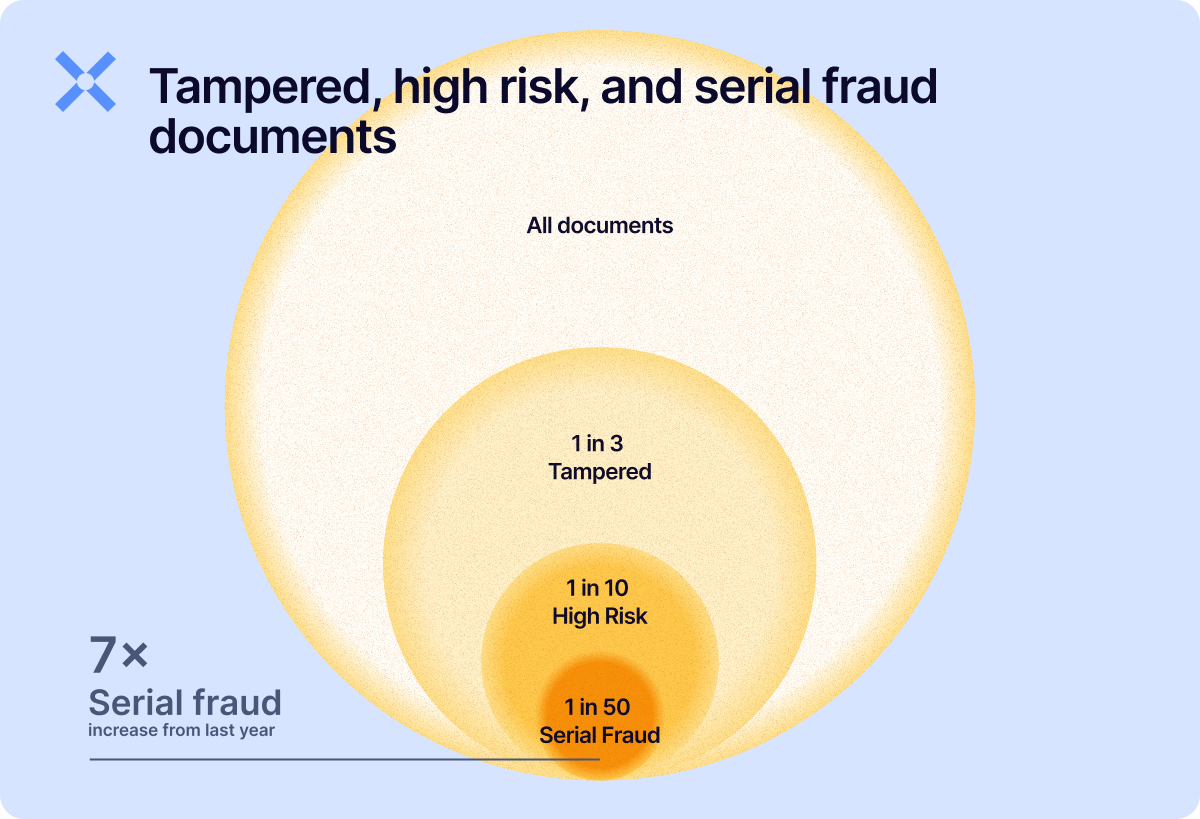
Of all the Docs we saw in 2025, 1 in 3 documents had their structural integrity tampered with, while nearly 1 in 10 were considered high risk, meaning tampering that indicated strong fraudulent intent. This class of documents was up 28.5% year-over-year (YoY).
Now, being able to tell the difference between a tampered document and one that shows signs of tampering with fraudulent intent is critical. It's the difference between stopping a fraudster, and ruining the experience of three good customers to do so.
Serial fraud, the industrial-scale reuse and (re)production of fraudulent documents to exploit weaknesses in onboarding and underwriting controls, was up a whopping 7x YoY.
Detection rates always fluctuate with improvements, but serial fraud has been a solid and repeatable detection mechanism for us for a while.
The divide between amateur and professional fraud
Document fraud now spans a spectrum from amateur opportunists to professional operations. Each requires different detection approaches.
- Amateur fraud. Relying on their personal documents (first-party fraud) or acquiring them from template farms, naive Gen AI use (no metadata stripping or transformation of image source), and simple editing techniques. Can be easier to catch, but only if you know where to look: relying on your eyes will get you into hot water.
- Professional fraud. Custom templates built outside catalogued farms, sophisticated Gen AI usage with metadata stripped, and deliberate detection evasion tactics. It's harder to catch, but network detection still works.
While we’ve only catalogued a representative sample of what template farms have to offer, what we see in our production data and samples indicates the most sophisticated organized operators often building their own infrastructure. This is consistent with the attack cluster data showing coordinated multi-document campaigns that no known template farm supports.
%20(1).png?width=1200&height=813&name=2%20-%20Industry%20Infographic%20(Figure%200.2)%20(1).png)
Key consideration for fighting back
To fight against fraud you need to hold on to two truths:
Fraud is subjective. So is efficacy. Define your battle ground
Here's the uncomfortable truth: what counts as "unacceptable risk" varies.
We’re opinionated: We ground our high-risk category in what we consider objective indicators of compromised document structure, integrity, and context.
But different industries (and companies within them) have different risk tolerances, which directly affects automation rates.
That's why our default risk profiles achieve 82–92% automation rates (documents auto-approved or declined) on day one, varying by industry.
Reaching rates up to 98% is possible, but requires clear risk policy definitions, not better technology. Most organizations have never defined these policies when it comes to documents. That's the real blocker.
There isn’t a single bogey man, nor silver bullet
Fraud is multi-faceted. Getting too absorbed by any one trend will leave you open to the tactics you aren’t paying attention to. Part of our research exemplifies this:
- Gen AI is the fastest growing threat, up 90% YoY (but it’s still small). Despite years of media and vendor hype, fully synthetic AI document fraud didn't take off until Nano Banana Pro's November 2025 release. Everything before that was noise. Everything after is a signal.
- Layered signals beat single indicators. Combining multiple detection layers catches 40% more fraud than relying on any single method alone. The best fraud isn't caught by any one signal. It's caught by the combination.
The threat landscape
9.08% of documents show high risk markers in 2025
28.5% increase from 2024.
That's nearly 1 in 10 documents showing evidence of tampering with fraudulent intent. And the growth isn't slowing.
%20(1).webp?width=1200&height=1003&name=3%20-%20Tax%20Details%20Bar%20Chart%20(Figure%201.1)%20(1).webp)
Not all documents are equally attractive to fraudsters. Why the variance? Some potential reasons based on document type:
- Tax documents are high-value (they are key in underwriting and onboarding scenarios) and low-verification (they can be hard to verify).
- Company information documents enable KYB fraud at scale, and businesses as fraud vehicles offer higher fraud and financial crime returns: you can transact higher amounts, charge higher amounts, etc.
- Utility bills are the path of least resistance for proof of address.
Format manipulation: The evasion tactic
.png?width=1200&height=1044&name=high%20risk%20percentg%20(1).png)
A quick glance at high risk rates across formats would lead you to believe digital PDFs are the riskier format.
But this is misleading.
Here's the reality: Scanned PDFs and images are never the original documents. Confirming fraud or authenticity is harder because the conversion process destroys evidence.
Signals you would get from analyzing a PDF, such as structural and metadata tampering, are either harder to pick up or gone. You might end up with only weaker signals, leading to Warning signals, instead of high-confidence fraud signals.
Without properly defined risk policies (see below), this can either lead to increase fraud exposure, or manual reviews that just won't go away. With the right ones, even light signals can be used to approve or reject documents.
.png?width=1200&height=627&name=5%20-%20Format%20Hopping%20Illustration%20(Figure%201.3).png)
The "lower" fraud rates for scans and images are undercounts, not signs of safety. If anything, scanned PDFs should be considered higher risk precisely because so much signal is lost.
When this is done with intent, we call this "format hopping."
1 in 4 image or scan submissions show signs of format hopping.
While not always fraudulent (some users genuinely don't know how to download a PDF), the pattern increases risk.
Format hopping examples:
-
Digital prints. When a PDF is turned into a pristine JPEG, and integrating that image into a PDF.
-
Print-to-pdf. When users "print to PDF" from their browser instead of downloading the original document.
- Screenshots. Screenshots are never the original document. Period. They're recreations that inherit none of the metadata or structural properties of the source.
-
Printing and scanning, or photographing a document. While some documents are legitimately provided only in printed form, many official documents these days exist in PDF format.
26.6% of images and scans have digital PDF alternatives.
With that availability, why are there so many scans/photos/screenshots submitted for review? Convenience or intentional evasion?
Businesses accept some of these formats to help customers more easily submit documents. But not all format changes are created equal, and that customer experience can come at higher cost.
Some denote higher levels of technical competency, and therefore should be considered higher risk than others, especially when paired with other signals in the document or at the submission level.
The metadata trap: Less useful than you might think
%20(1).png?width=1200&height=1055&name=6%20-%20Metadata%20Bar%20Charts%20(Figure%201.9)%20(1).png)
While High Risk documents are over 5 times more likely to have their metadata stripped than Normal documents, here's the catch: relying on metadata alone is a strategy doomed to fail.
Professional fraudsters can produce documents with correct metadata. Metadata’s just one input among many, not a detection approach.
Here's an example of this trap: finding traces of editing tools in metadata:
%20(1).png?width=1200&height=968&name=7%20-%20Risk%20Indicators%20Bar%20Chart%20(Figure%201.10)%20(1).png)
At first glance, you might assume that documents revealing these editors in metadata may warrant immediate scrutiny or auto-decline, depending on your risk appetite.
But the challenge is distinguishing intent: Adobe Acrobat and Photoshop are legitimate production tools for many official document issuers.
Correctly distinguishing tool use versus forgery can make or break your customer experience and automation goals. It’s not all about metadata giveaways.
Threat intelligence: The fraud supply chain
If you want to understand the document fraud landscape, follow the infrastructure that makes it possible.
Template farms
The entry point for fraud, template farms allow fraudsters to download editable templates and submit them as formal evidence.
The economics are striking: $28.29 is the average barrier to entry for document fraud in 2025. Less than a nice dinner.
Threat intel stats: Template farms February 2026
A note on methodology: These stats are a staggering jump up from what we covered in 2024, with both websites and document templates nearly doubling. But this growth reflects both actual expansion of the fraud economy and our improved cataloging of existing farms. The infrastructure was already larger than we knew.
%20(2).png?width=1200&height=1119&name=8%20-%20Industry%20Infographic%20(Figure%200.2)%20(2).png)
Most farms target documents from the most mature financial systems, but nearly all are represented, and we expect that as we expand research, we will find more farms specializing in specific regions.
However, given the heavy flow of international web traffic we see to farms specializing targeting mature financial systems, we expect this pattern to hold.
Account farms
Account farms provide pre-verified infrastructure, giving access to already onboarded accounts to be used at will.
Threat intel stats: Account farms 2026
Account farms sell the end product: Fully onboarded, KYC-passed accounts that fraudsters can use immediately. No need to create fake identities from scratch: you can buy ready-made access.
How do criminals create onboarded accounts?
-
Synthetic identities. Combine fabricated and stolen data into personas that pass basic verification.
-
Account takeovers. Hijack legitimate accounts from real people.
-
Shell companies. Pass basic checks with minimal documentation.
Account farms are the next layer of the fraud supply chain — and they're growing.
Supply chain economics
The fraud supply chain has professionalized:
|
Low barrier to entry With rates less than $30 and minutes to customize, anyone can become a document fraudster, or expand their available opportunities for committing fraud. |
|
Specialization Template farms, account farms, and generators serve different stages of the fraud workflow. Like any mature industry, roles have differentiated. |
|
Scale The combined infrastructure supports thousands of fraud attempts daily. This isn't a cottage industry anymore. |
4 trends reshaping the threat landscape in 2025-2026
Now that we’ve established the current landscape, let's cover some new and evolving threats that are still taking shape.
Document generators
Occupy a grey area. Paystub generators and invoice creators serve legitimate purposes for freelancers and small businesses. They also serve criminals with readily available fake documents. Detection is possible; determining intent requires context. |
Cross-border leakage
Criminals are exploiting risk teams' unfamiliarity with foreign institutions to evade verification. For example: a criminal takes a utility bill from a company that operates exclusively in the UK, adds an Italian address, and submits it as proof of address to a German bank. Templates are going global. |
Serial fraud
Sophisticated operators are building custom document infrastructure at scale. This is why 98.3% of serial fraud detections have no attribution to known template farms. The most sophisticated professional fraudsters aren't buying templates, they're making them. And this trend is accelerating. |
Generative AI.
While the risk has been looming over the horizon, Nano Banana Pro's November 2025 release finally made the creation of fully synthetic complex documents (bank statements, utility bills, etc) possible and accessible. |
While document generators and cross-border leakage are still under investigation and somewhat self explanatory, Serial Fraud and Generative AI already have a lot of data behind them as you’ll see below:
Serial fraud: The organized threat
We defined the category of serial fraud in September 2024:
%20(1).png?width=1200&height=729&name=9%20-%20The%20Scale%20Bar%20Chart%20(Figure%202.3)%20(1).png)
23% of all high risk documents
show signs of serial fraud.
It’s not just growing. It's becoming a larger share of the fraud we catch, amounting to:
70,000 median serial fraud detections per month.
Where it concentrates
%20(1).png?width=1200&height=729&name=23%20-%20Serial%20Fraud%20Concentration%20by%20Vertical%20(2)%20(1).png)
While marketplaces are overwhelmingly exposed, Payment providers, especially those that are marketplace adjacent and are responsible for seller onboarding onto the marketplaces, are similarly exposed.
Meanwhile, gaming and insurance see modest but measurable activity.

Outside these sectors, serial fraud may seem rare when looking at the percentage distributions, but this is skewed by the scale of attacks on marketplaces.
Serial fraud impacts all sectors.
.png?width=1200&height=955&name=serial%20fraud%20detection%20(1).png)
We catch serial fraud by identifying behavioral patterns across documents, not by maintaining a database of known bad templates. When a template shows up that we've never seen before, we still catch it because the pattern of reuse is visible in the network.
Fundamentally, the difference we are talking about here is actually one of attribution: the 1.7% that have a template farm attribution would still have been caught by our core serial fraud detection capabilities.
This difference in attribution is driven by two things:
-
The first is that the rabbit hole of template farms is far deeper than what we have mapped so far.
-
The second is what we see in our own production data: The most sophisticated professionals aren't using off-the-shelf templates from farms. They're making their own to create novel large scale attacks.
23,352 documents in a single cluster
The largest serial fraud cluster we detected in a single customer included 23,352 documents.
%20(1).png?width=1200&height=877&name=11%20-%20Attacks%20Clusters%20(Figure%202.9)%20(1).png)
But it wasn't 23,352 copies of the same template.
It was a coordinated operation using multiple different document types as part of the same fraud campaign.
This is what network detection catches that document-level analysis misses.
A fraudster submitting Bank of America statements, Chase statements, and Wells Fargo statements might look like three separate applicants at the document level.
At the network level, we see the connections: same underlying patterns, same fraud operation, same cluster.
That’s not to say certain templates aren’t more heavily targeted:
.png?width=1200&height=981&name=4X%20the%20rate%20in%202024%20(1).png)
Interestingly, the largest cluster we saw this year was 1/3rd the size of the largest we saw in 2024, which reached just over 70,000 documents.
We attribute that to the usual pattern we see over time in institutions we protect: fraudsters adapt and increase their iteration speeds to try and get past our defenses.
80% of serial fraud campaigns last less than 25 days
.png?width=1200&height=1238&name=fraud%20clusters%20(1).png)
When looking at the distribution in more detail, 3 main patterns emerge:
- <5 days. Rapid burst attacks (around 1,500 clusters fit that category)
- 5-25 days. Standard hit-and-run covering 80% of campaigns.
- 25-175 days. The long tail of persistent operations or disorganized groups coming across the same template online.
What this means for detection:
- Processes and systems that require weeks to identify patterns will miss most campaigns entirely. By the time you've caught onto one attack, you will have missed 3 more. Speed matters.
- Recently-formed clusters warrant higher scrutiny. By the time a cluster is "established," it may already be burned.
Generative AI fraud: the emerging threat
Let's be clear about where we are with generative AI document fraud:
~5% of fraud declines are from AI-generated documents in our adaptive decisioning sample.
It's small. But it's growing faster than anything else.
%20(1).png?width=1200&height=868&name=14%20-%20Gen%20AI%20detection%20(Figure%202.16)%20(1).png)
This incredible growth is obviously a combination of two factors:
- Increased detection capabilities. We have been rolling out more and more sophisticated detection capabilities over the past year.
- Actual fraud growth. Yes, we're catching more, but there is also more to catch.
The Nano banana moment
In fact, for most of the year, Gen AI document fraud was not theoretical but largely ineffective on complex documents.
Detection numbers were low, and the media hype outpaced the actual threat, something we heavily covered in our multiple webinars covering the up-to-date limits of the threat.
Then Nano Banana Pro launched in November 2025 and totally changed hte game.
.png?width=1200&height=807&name=15%20-%20Fraudsters%20Clusters%20Graph%20(Figure%202.13).png)
The mid-march social media obsession with expense receipts was really driven by the fact that receipts are simple documents with no standard layout that needs adhering to, and was all the models could really handle without messing.
Unlike previous models that struggled with text consistency in complex documents, Nano Banana Pro can generate nearly perfect documents with very few, if any, instances of mangled text.
It can even do the math on the documents it creates correctly, adjusting totals when you add line items.
We've come a long way since mid 2024:
%20(2)%20(1).png?width=1200&height=736&name=16%20-%20Document%20Generation%20Examples%20(Figure%202.18)%20(2)%20(1).png)
A large portion of the document fraud we've seen this year came at the tail end of the year off the Nano Banana Pro launch.
Document image generation has markedly improved. For a deep dive on Gen AI document fraud, see our dedicated analysis.
How amateur and professional fraudsters differ in Gen AI use
%20(1)%20(1).png?width=1200&height=928&name=17%20-%20Detection%20Metadata%20Pie%20Chart%20(Figure%202.19)%20(1)%20(1).png)
Most Gen AI fraud is amateur hour. Users prompt ChatGPT or Gemini, get an output, and submit it directly (with all the telltale metadata intact). Basic checks catch them.
But the proportion of sophisticated fraud is growing. As fraudsters learn, the easy catches will disappear.
But what separates the two? What makes professionals harder to catch?
Amateur vs professional Gen AI fraud |
|
Amateur Gen AI fraud
At the core, this risk is a numbers game: with generative AI weekly active user numbers reaching into the billions, only a fraction need be tempted to commit fraud to create overwhelming odds. The challenge is that these fraudsters look like everyone else: these are one-off frauds, with no previous behavioral signals to correlate. Luckily, most are unsophisticated and will leave metadata and other obvious triggers. |
Professional Gen AI fraud
Sophisticated actors using AI to scale existing operations. Metadata stripped, format hopped, tested before submitting. They require advanced detection: image forensics and model fingerprinting. Most importantly, they scale their creations and automate. |
The automation threat
The sleeper threat isn't chatbot-based fraud. It's automated pipelines.
The document fraud automation workflow:
- Generate 100 documents via API.
- Use a second model to quality-check outputs.
- Combine with leaked PII to create complete application packages.
- Submit at scale.
This industrialization isn't theoretical. OnlyFake demonstrated batch creation of fake documents in 2024, even with limited generative capabilities.
The infrastructure exists, and the models are getting better at enabling automation at scale.
Where fraud concentrates
Who is most at risk from the document fraud threat?
Industry verticals and use cases
We primarily work within 7 key verticals: marketplaces, gaming, payment providers, banks, lenders, insurance, and screening services (more details available in our methodology section).
But not all verticals face the same fraud profile: nearly 1 in 5 marketplace documents have high-risk markers.
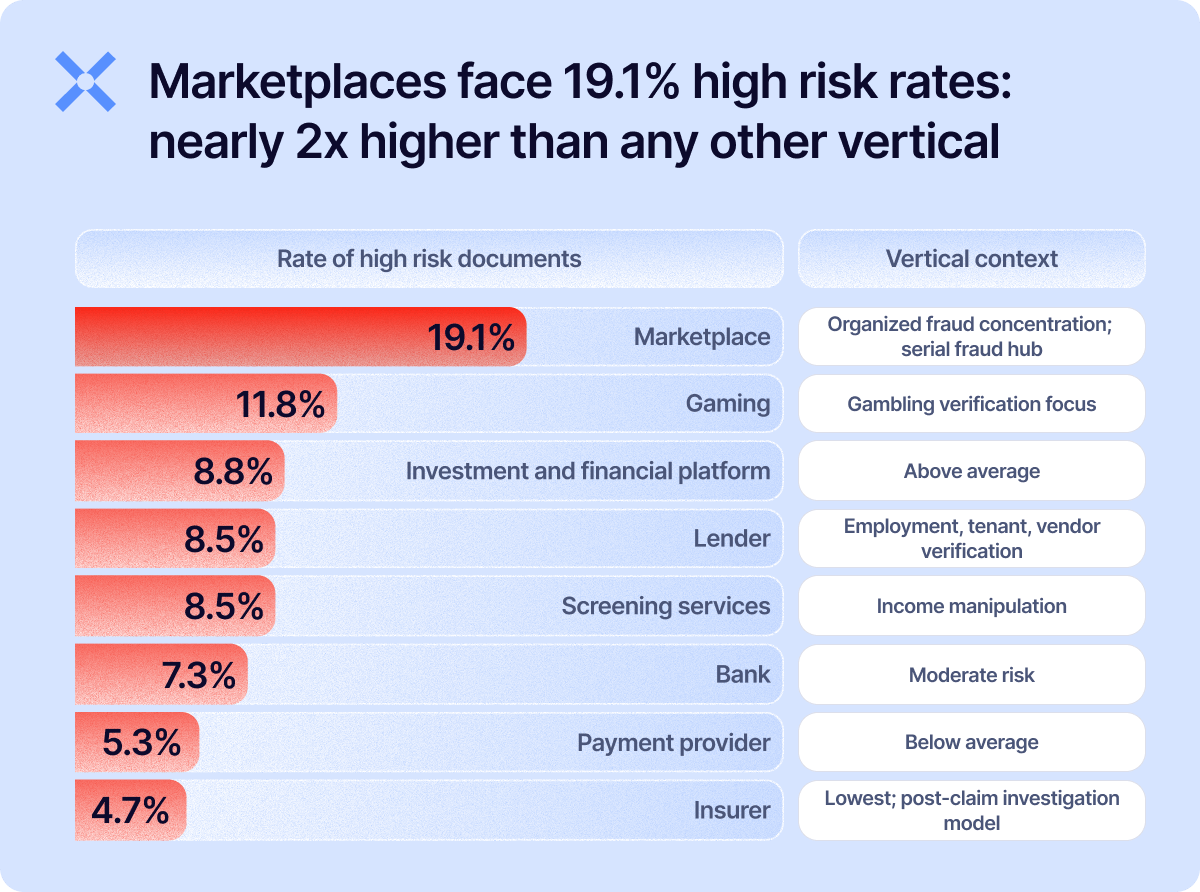
High volume, rapid onboarding, and valuable accounts create perfect conditions for organized fraud.
The 86% of serial fraud that concentrates in marketplaces mentioned earlier tells the same story.
The pattern we see repeats itself across sectors: the higher the velocity, and the more focused on b2b the flow, the face higher risks.
We see the same thing when breaking down the risks by use case: "vendor onboarding" is an often overlooked document verification workflow for large institutions, but supplier fraud and business email compromise scams often rely on doctored invoices and fake certifications.
%20(1).png?width=1200&height=875&name=19%20-%20High%20Risk%20Bar%20Chart%20(Figure%203.1)%20(1).png)
High-risk regions
Since we received documents from over 135 different countries, we've focused on countries where more than 100,000 documents were received and were not overly concentrated from any one use case or customer.
Bangladesh stands out as an extreme outlier with just over 50% of documents falling into high risk categories. Overall, most countries sit between sit in the 20 to 10% range.
%20(1).png?width=1200&height=1160&name=21%20-%20Map%20High%20Risk%202%20(Figure%203.3)%20(1).png)
From detection to decision
Time for actionable insights on what to do about these threats.
Network detection vs single document-level analysis
The industry default is document-level analysis: examine each document in isolation, catch obvious manipulation, maybe compare it to a library of templates, move on.
Network detection is different. We connect patterns across documents, customers, and time, leverage signals beyond the documents alone. We catch coordinated, industrial scale serial fraud attacks that look normal at the individual document level.
What actually triggers declines
While we pride ourselves in our network-level capabilities and all of the other detection capabilities, the reality is that the clear majority of declines are driven not by a single detection signal, but by multiple detection signals operating in concert.
.png?width=1200&height=948&name=network%20detection%20signals%20(1).png)
Risk tolerance: The questions you need to answer
We could give you a prescriptive framework. Signal X means action Y. But that would miss the point.
Fraud is subjective. What's unacceptable risk for one organization is acceptable for another. The questions matter more than our answers.
Some signals indicate high-confidence fraud across virtually all verticals:
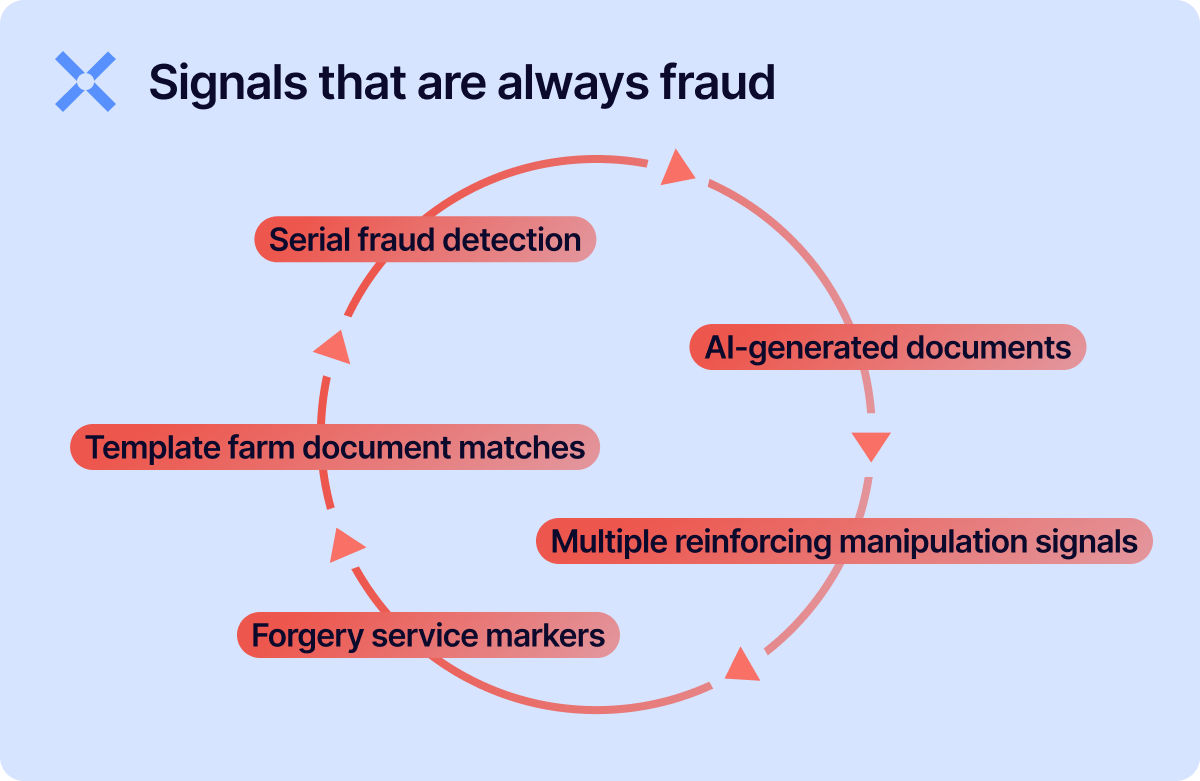
If you see these, decline. The false positive rate is negligible.
Signals that require questions
- Screenshots. Evidence of fraud, or just a user who doesn’t know how to download a PDF? Your answer depends on your vertical, your customer base, and your fraud exposure.
- Print-to-PDF. A red flag, or standard behavior for certain demographics? Some user populations legitimately struggle to download PDFs properly.
- Single manipulation signals. Enough to decline, or does context matter? A single anomaly might be an artifact. Multiple anomalies are a pattern.
- Online generator-created documents. Fraud, or a freelancer using a legitimate paystub tool? The tool is the same; the intent is different.
These questions don't have universal answers. They have your answers.
Why risk policy matters more than detection tools
Detection identifies signals. Decisioning applies context.
Without clear risk policies, you're left with every flag requiring human review, no differentiation between high-confidence fraud and edge cases, and reviewer fatigue leading to missed signals.
%20(1).png?width=1200&height=948&name=23%20-%20Policy%20Clarity%20Automation%20Improvement%20Pie%20Charts%20(Figure%204.4)%20(1).png)
Most organizations have never defined these policies. That's the real blocker.
82-92% automation from day one
We have various out-of-the-box configurations tailored to specific industry use cases that provide a range of fully automated decisions (auto-approval and auto-decline), depending on risk appetite.
The differentiator isn't technology. It's:
- Using any document attribute as a decision signal. Format, classification, issuer, country, fraud indicators, verdict: all of these can drive automatic decisions if you've defined the policy.
- Defining explicit policies for edge cases. What do you do with screen photos from certain countries? Generator-created documents in certain use cases? Single manipulation signals on certain document types
- An ongoing partnership. 98% automation means flagging false negatives and positives that have never occurred before, defining clear answers to them, and adjusting models appropriately.
The Adaptive Decisioning leverage
Detection without decisioning creates operational burden. Every flag requires review.
Detection plus decisioning creates operational leverage. High-confidence fraud gets blocked automatically. Low-risk documents approved automatically. Human expertise gets reserved for genuine ambiguity.
We don't just detect fraud.
We help you define and operationalize the risk policies that turn detection into extreme automation.
7 steps you can take today |
|
|
1. Measure your actual automation rate. |
What percentage of documents get auto-approved or auto-declined without human review? If you don't know, you can't improve it. Set a benchmark and identify what's sending the rest to manual review. |
|
2. Review your existing risks. |
Take a sample of documents tied to confirmed fraud, and examine their characteristics: what format do they have, what kind of documents are they, what region do they come from, what the commonalities in their metadata? This is the first step towards establishing a document-focused risk policy. |
|
3. Flip your format risk model. |
If your current rules treat scanned PDFs and images with the same risk profile as PDFs in order to satisfy user experience, it’s time to challenge that assumption. Consider treating non-native formats as elevated risk by default. |
|
4. Audit your serial fraud visibility. |
Are you analyzing documents in isolation, or do you have any network-level detection? If a fraudster submits the same template to 50 applications with different names, would you catch it as one attack or see 50 unrelated submissions? |
|
5. Calibrate detection speed to campaign duration. |
Most serial fraud campaigns burn out within 25 days. If your pattern detection requires weeks of data accumulation, you're catching campaigns after they've already succeeded and moved on. Prioritize detection methods that work on shorter time horizons. |
|
6. Stress-test your Gen AI detection. |
Run a controlled test: generate a document with ChatGPT or Gemini, then screenshot it, crop it, modify it, or some combination of the three to strip its metadata, and submit it through your pipeline. Does it get caught? The 30% of Gen AI fraud requiring advanced detection will grow as fraudsters learn. |
|
7. Check if your institution is on the menu. |
Template farms now offer 300,000+ documents imitating 15,000+ issuers. If you issue documents that others rely on for verification (bank statements, utility bills, tax letters), check whether your templates are being sold. If they are, your downstream partners are targets. |
Conclusion
Document fraud now operates on a spectrum: amateur opportunists are armed with $28 templates and ChatGPT, professional operations are building custom infrastructure at scale.
Both ends are industrializing. Both are evolving. And the line between them is blurring.
Amateurs are getting better tools. Template farms are growing. Gen AI is accessible. Simple edits are easier than ever. What's catchable today may not be catchable tomorrow at least not with the same methods).
Professionals are getting more sophisticated. Custom templates built outside our catalogued farms. Metadata stripping and format hopping as standard practice. Automation pipelines that generate and quality-check documents at scale.
Detection gets you partway there. Decisioning gets you further.
But navigating this landscape understanding which signals matter for your industry, defining your risk appetite, and adapting as threats evolve requires a partner.
That's what we do.
Methodology
This report analyzes non-ID document fraud patterns across banks, lenders, payments providers, marketplaces, insurers, and screening services. Our analysis draws on the insights of the 170 million+ documents processed since our founding in 2019, with a focus on 2025 production data and ongoing threat intelligence monitoring, normalized for customer mix changes.
Key limitations to keep in mind:
The following limitations slightly narrowed the scope of our research:
- Our Gen AI detection capabilities matured throughout 2025. Q1 numbers reflect earlier detection states, so year-over-year comparisons should account for capability evolution, not just threat growth.
- Geographic and use case rates require minimum sample sizes for statistical validity. Where sample sizes are smaller, we note it or exclude the data.
- High-volume marketplace environments show elevated fraud rates due to concentration effects. We provide context where this matters.
Definitions:
The following definitions will help you understand the contents of the report.
- High risk. Signs of tampering with fraudulent intent, or synthetic documents
- Warning. Higher than expected risk, due to unusual origin or artifacts warranting review, but not necessarily indicative of fraud
- Normal. No evidence of manipulation
- Trusted. Known authentic document consistent with past practices and context.
- Risk profiles: Pre-built, industry-specific decision frameworks that auto-approve, auto-decline, or escalate documents based on their structural characteristics and detection results.
- Adaptive decisioning. A managed service that tailors decision rules to each customer's risk tolerance and fraud landscape, automatically routing documents to approval, decline, or manual review.
Industry verticals
Here are the industries we collect documents from:
- Marketplace. E-commerce platforms, retailers, or any service connecting buyers and sellers—including B2B and B2C models.
- Payments provider. Payment service providers offering merchant accounts with a money transfer license (US) or EMI license (EU). Includes providers that perform KYC/KYB due diligence on customers or merchants.
- Bank. Financial institutions operating under a banking license.
- Lender. Non-bank credit providers, including private lending and alternative finance platforms.
- Insurance. Institutions offering insurance products and services.
- Screening services. Document fraud detection in tenant screening, employee screening, and immigration screening sectors.
- Gaming. Gambling and prediction market platforms.
Use cases
We collect documents related to the following use cases:
- Claims processing. Assessing and settling insurance claims submitted by policyholders.
- KYC. Verifying customer identity and assessing risk to meet regulatory compliance requirements.
- KYB. Conducting due diligence to verify a business entity's legitimacy and background.
- Loan Underwriting. Assessing a borrower's creditworthiness and financial risk.
- Tenant screening. Assessing the background, financial stability, and rental history of prospective tenants.
- Vendor onboarding. Vetting vendors to establish business relationships and ensure compliance with company standards.
- Auditing. Reviewing financial records and business processes to verify accuracy and regulatory compliance.
- Employee screening. Assessing the background, qualifications, and criminal history of job candidates.
- Immigration screening. Verifying the eligibility and background of individuals seeking immigration approval.
- Policy underwriting. Assessing the risk profile of individuals or assets for insurance approval.
For more methodology details, glossary of fraud types, and additional resources, visit the Document Fraud Detection guide or explore our types of document fraud analysis.
Fraud awareness, examples, and lessons
Learn more about fraud in specific industries, best practices, and targeted documents.
View all
Fake New York business licenses are risky in 2026. Whether it’s to provide jurisdictional privileges, or renew the ...

When we think about APP fraud, our hearts go out to the victims. But in 2026, banks in the UK are shouldering a ...

If you've seen as many template farm websites as we have, things start to blur. Hundreds of sites are selling ...

Key takeaways AI receipt generators are available. A simple Google search can reveal the top tools on the market. ...

Whether it’s a forged medical diploma or a suspicious Australian degree used for a Hong Kong visa application, ...
Money moves faster than ever in 2026. Instant payments, digital wallets, embedded finance, online marketplaces, ...