





The ACAMS Annual AML & Anti-Financial Crime Conference held in Hollywood, Florida, is one of the most anticipated events in the anti-money laundering community and one that offers a yearly chance for tech companies like ours to showcase directly to fintechs and traditional financial services how technology can help the fight against financial crime. Last month, the PwC Hackathon, which Resistant AI has previously won twice, again allowed us to make artificial intelligence the star of the show.
Provided with over 2.3 million synthetic customer and transaction data points and just three days to analyze them, the Resistant team applied our expertise honed through working with leading payments firms and neobanks to bring to light examples of fraud, money laundering, sanctions evasion, and other suspicious behaviors. Yet the explainable manner in which our tool contextualizes the stories within the data was what set our approach apart.
The trouble with The Tribble
To find bad behavior, our team first needed to understand the scope of the world we were provided with—no mean feat when data points number in the millions and the clock is ticking. Money movements and account relationships are a convoluted, inherently complex network of connections in both the real world and in the synthetic datasets we were working with. If that wasn't enough, we also integrated into this network all of the supplemental knowledge provided for the Hackathon: IP address data, contact numbers, physical addresses, VPN information, and the like. In real world datasets, still more information can be introduced, like device and location data. Visualizing the entirety of the available data produced the interconnected network—some might say tangled mess—below, which we affectionately nicknamed “The Tribble”.

The Tribble in all its glory.
But jumbled as The Tribble seemed, in the midst of chaos there is opportunity: perhaps counterintuitively, the more data you compile, the more you realize that things aren't, in fact, all that chaotic. Transactions by their nature don't exist in isolation, so leveraging data points relating to individual entities and the transactions between them can—with the right tool—establish relationships, patterns, and ultimately the broader context of the slice of the world our data describes. For our team, that tool is AI-powered forensic analysis specifically designed to condense masses like The Tribble into something more manageable and, more importantly, something investigators can make sense of.
How we trimmed The Tribble, or, the ensemble approach
But it wasn't magic how our artificial intelligence began to make these groupings, nor was it one grand unified model hard-wired to focus on hyper-specific AML tactics. Instead, Resistant AI's distinctive approach relies on layers of simpler models that each highlight statistically anomalous behaviors across a range of dimensions.
Models grouped to focus on a certain dimension—which we call detectors—act like a sifting table for financial misconduct. Data signals, or indicators, layer on top of one another—some may strongly suggest suspect behavior, some maybe only weakly. But once combined, these signals provide a comprehensive assessment of what constitutes normal customer behaviors as well as out-of-the-ordinary activities that create or break up noteworthy patterns.
It's this multi-layered data-driven strategy that allows our tool to act as a highly accurate yet flexible countermeasure against unusual activities—whether we've seen those activities before or not. We call this the ensemble approach.
To make the ensemble approach more tangible, here are a few of the detectors that most effectively revealed hidden patterns and relationships—suspicious behaviors—in the Hackathon dataset.
Anomaly clustering
Our first step was to apply simple, unsupervised clustering to identify and group similar data points—clusters. This, of course, also helps you to identify outliers at the same time. The beauty of clustering as a starting point is that it is completely agnostic to the particular problem you are trying to solve and doesn't require labels: this technique can be used on almost anything you plug into it.
On the other hand, the clusters you get as the output may not be meaningful at all—anomalies aren't always nefarious and can be false alarms. So anomaly detection isn't always a strong indicator of wrongdoing, but more of a first foothold when working with a mass of many different types of data. What's more, the ensemble approach's multiple overlapping detectors give us many strong options as to how to follow up: any clues uncovered by clustering will always be reinforced and ultimately confirmed by other findings.
Anomalous amounts
This type of detector takes clusters a step further. By first using historical transaction data to define the amounts that certain customer segments can reasonably be expected to send and receive as part of their normal activities, abnormally large incoming or outgoing amounts stuck out like sore thumbs—and suggested activities that should be investigated by still more detectors.
Having machine learning perform this type of assessment allows not only for automatic (rather than manual) analyses, but also for dynamic rather than static thresholds of investigation. So rather than make generalities for a heterogenous customer base—e.g. a rule stating that every transaction over $10,000 is suspect by nature—investigative bandwidth can instead be directed to accounts making large moves that are truly out of the ordinary for that customer, regardless of the actual dollar amount in question. So a business that regularly makes five-figure transactions won't be needlessly held up, but a five-figure transfer from Average Joe who never spends more than a few hundred dollars in one go will get extra attention.
Particularly when working with real datasets rather than the synthetic ones here, this also allows us to perform more sophisticated analyses of the amounts being transacted. Common tactics like smurfing / limit avoidance up to more money laundering tactics relying on mathematical operations and patterns of individual digits can be uncovered with ease using a data-driven approach to anomaly detection.
Intelligent sanctions evasion screening
Subtle manipulation of spelling or transliteration is a common tactic to attempt to avoid matches on sanctions lists; these attempts are often successful if a traditional sanctions screening regime acts only on one-to-one matches against sanctions lists. By applying fuzzy matching to customer names, we uncovered variations in spelling that suggested nefarious activities by sanctioned parties.
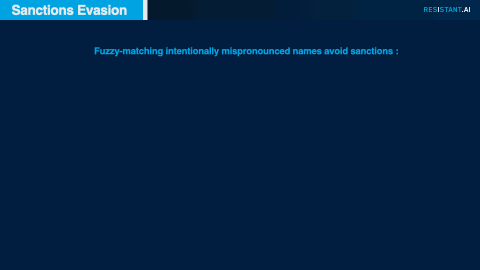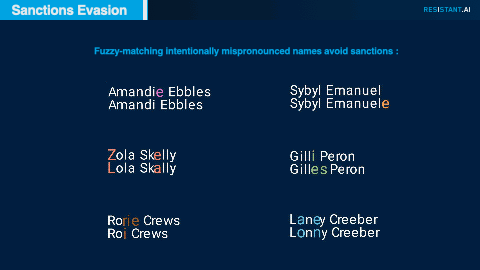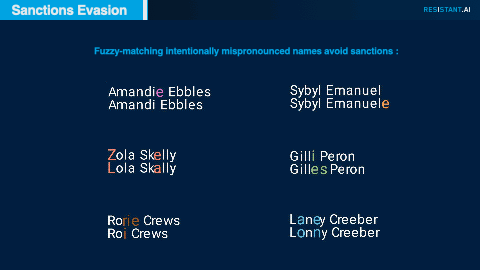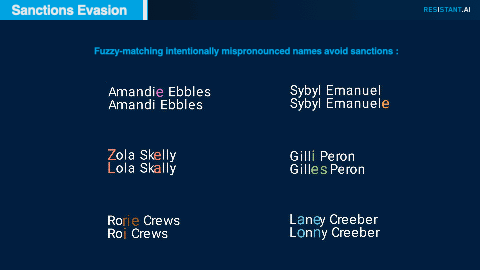
Some noteworthy examples of successful fuzzy matches.
Large language models (LLMs) for adverse media screening
One of the hairiest parts of our dataset was a tangle of simulated internet search results for negative news reports. This presented a problem, as simple keyword searches and classical machine learning methods find it very difficult to model things like negation and sarcasm— linguistic tasks that humans take for granted would return an unmanageable number of false positives. After all, not all news is bad news.
But again our team's technical expertise in many realms of machine learning helped us out. By further enhancing a pre-trained LLM with training examples of the tricky linguistic tasks we were after, Resistant was able to effectively produce an AI model that understood not just the content but the sentiment of the news reports available to us.
In parallel, we were able to extract from the same media information about entities, which we could then check against customer-provided information for discrepancies—a.k.a. new developments that have come to light or attempts to cover up their activities. Together, these allowed us to assign higher risk associations with negative headlines without interference from positive press.
 Example entities, media context, and associated risk assessment after running sentiment analysis.
Example entities, media context, and associated risk assessment after running sentiment analysis.
Predicting transaction descriptions
As with many real-life transfers, financial transactions in the Hackathon dataset included text descriptions along with the amounts and counterparties. These consisted of industry-related codes and shorthand, anything from the name of the credit card provider to cryptocurrency ticker symbols.
Adapting an approach similar to that of Chat GPT but training it only on the description texts provided for this exercise, our team was able to predict common descriptions character by character. These predictions could then be compared and classified to understand what normal transaction descriptions should look like and what abnormal descriptions look like.
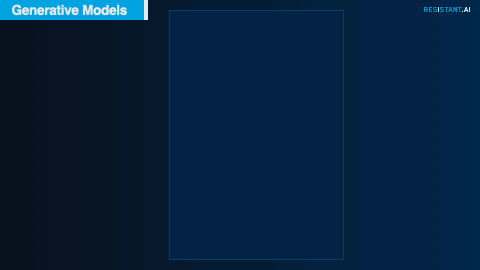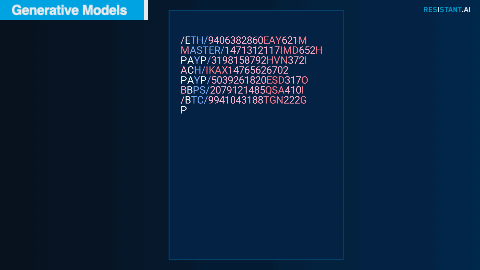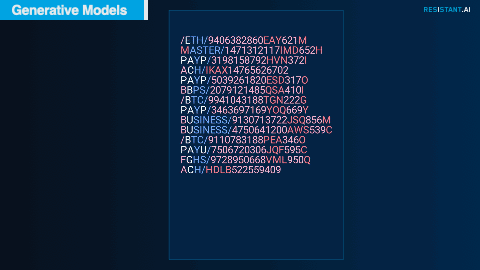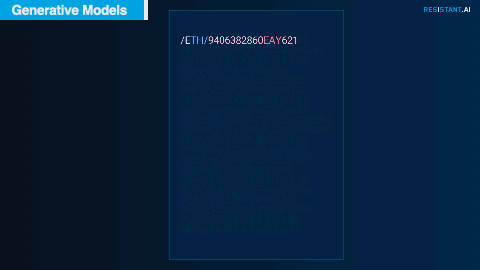
Example descriptions, including cryptocurrencies, major credit cards, and transfer methods. Blue represents higher certainty that the model's prediction is correct.
Graph analysis of suspicious typologies
Perhaps the most powerful tool in our toolbox, however, came as we analyzed the actual flow of transactions that made up The Tribble. For rule-based systems and most machine learning approaches, the sheer size of the graph is intimidating if not an outright blocker.
But once we had broken down the entire dataset into clusters, transaction flows became much more manageable subgraphs that could essentially be analyzed individually. Certain identifiable movement typologies like splitting then merging large amounts, circular transactions, money muling, and more then became abundantly clear rather than buried among millions of normal transactions. What's more, these seldom indicate anything other than suspicious activities.
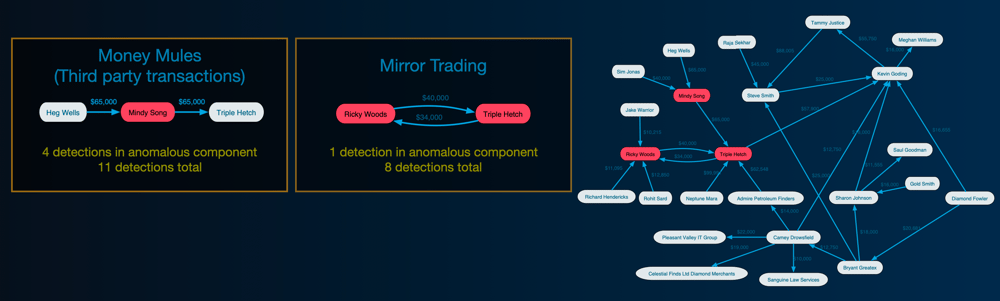
Two notable typologies—money muling and mirror trading—were discovered and separated from a single cluster of less suspicious transactions.
Tales from the data
By applying the ensemble of AI forensics detectors described above and many others, we began to untangle The Tribble. Cutting through the chaos exposed numerous fraud clusters that covered the spectrum of suspect behavior, including:
- Money mules
- Mirror trading
- Smurfing
- Anomalous high-value transactions
- Entity consolidation at a high-risk institution
- Suspicious transaction details
- Sanctions/PEP evasion

The fraud clusters of various sizes that the Resistant AI team uncovered using the ensemble approach.
But we didn't stop solely at uncovering entities' bad behaviors. The precision and combined info that contributed to each of our findings also allowed us to plausibly reconstruct stories that cast light on the strangeness of certain activities, going beyond statistical certainty to confirm our findings in a very human way.
The Receptionist
Maggie Barelty of Elk River, Minnesota, works as a receptionist. By all accounts, she is a typical bank customer who displays consistent behaviors and modest tastes. Yet one day, her transaction history showed that she suddenly moved to Russia, complete with an established residential address and a Moscow phone number. While there, she apparently opened up a brand-new credit card and used it to make two high-value transactions to the Cayman Islands totaling $100,000. She then just as suddenly moved back to Elk River.
This is a clear-cut case of how a series of anomalous high-risk actions contributed to enhanced scrutiny of this account including:
- High frequency of phone number/address changes
- Higher-risk countries (new residence and money transfer location)
- Elevated aggregate value transactions involving new counterparties
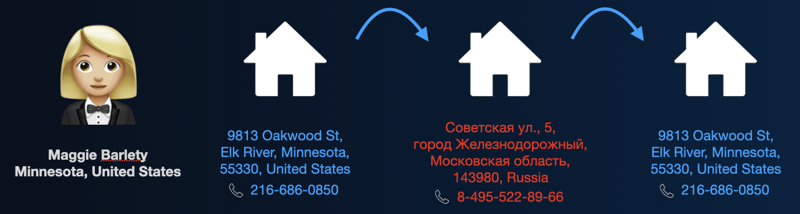
A map of how Maggie—or someone using her identity—went from receptionist to globetrotter and back again. Highly suspicious.
The Mechanic
Hanan Willman is a mechanic living in Siberia. One day, he received a $89,000 payment from Rick Henny, ostensibly of the US. While a large, anomalous payment like this was in and of itself something of interest, the concern for this transaction was compounded as we looked at the broader context supplied by all the other info at hand about the counterparties.
Rick Henny has an address with a US postal code, but a physical address seemingly in Germany. Records also show that Henny retains a 51% ownership in a Ukraine-based company. While our tool does not take geopolitical events into account, the involvement of high-risk jurisdictions and the timing of this transaction—approximately two months prior to the Russian invasion of Ukraine—suggested that suspicious behavior was afoot, such as moving funds should conflict and sanctions make them otherwise inaccessible.
Stringing together even this small handful of data points is a process that would take a manual reviewer no small amount of time, assuming they looked at all of these points at all. But with an AI-powered investigation tool, just a few moments revealed key factors that contributed to a high-risk assessment of this interaction:
- Anomalous fund transfer
- Address discrepancy
- Sender is a controlling shareholder
- Transactions involving high-risk jurisdictions
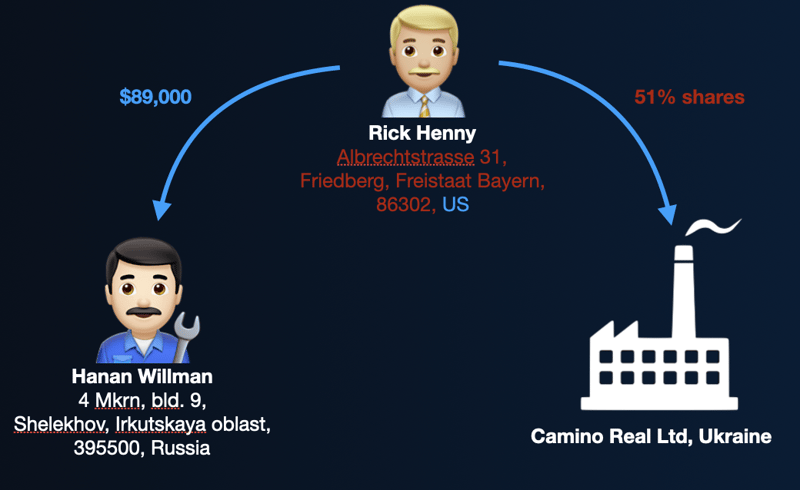
Rick Henny at the crux of a high-risk international relationship.
The Centerium Gang
What became clearer as we continued to dig, however, was that the risky clusters we identified weren't necessarily always just suspicious individuals running schemes on their own. When assessed in the context of the entire dataset, many clusters were revealed to be merely sub-clusters, or constituent parts of large, coordinated financial crime rings.
One of the larger clusters was particularly startling. As we were running our analysis, we noticed a group of entities whose risky behaviors repeatedly triggered warnings throughout the dataset for just about anything you can think of: anomalous transaction descriptions, past money laundering violations uncovered through adverse media searches, and transaction typologies that are highly suspect. But in addition to their willingness to engage in shady behaviors, these entities all had one thing in common: they were all using the same bank. Appropriately, we nicknamed this crime ring “The Centerium Gang” after the fictional Centerium Bank at its heart.
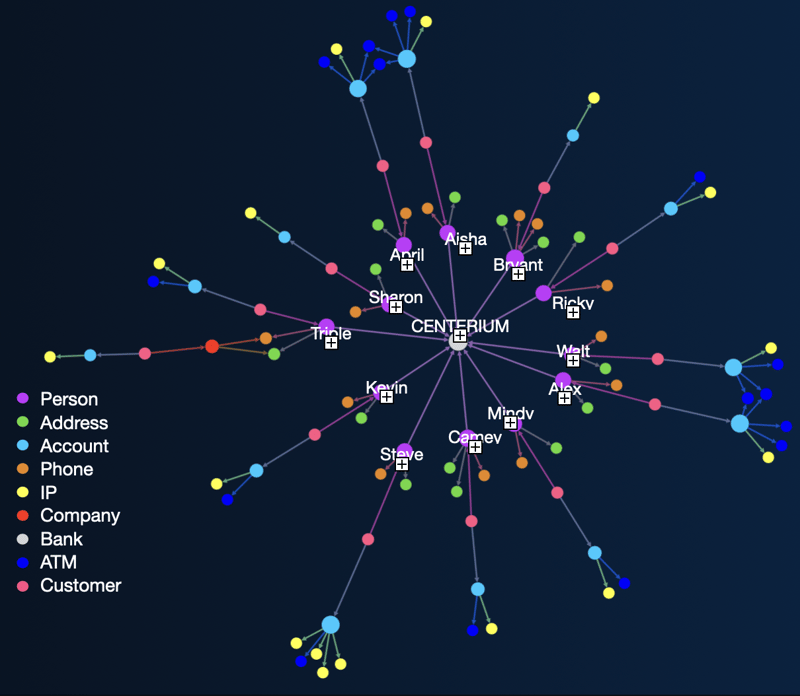
Centerium Bank, wittingly or not, was the hub around which 12 suspicious actors revolved.
Clearly illustrating the interconnections among actors that otherwise could be dismissed as unrelated wrongdoers served a twofold purpose. First, this cluster confirmed that we had correctly identified the individual financial criminals that made up this web—false positives appearing in so high a density would be improbable to the point of impossible. More importantly, however, uncovering the shared institution at the heart of this crime ring also revealed the reason why this web was able to function and flourish at all: this bank was, in one way or another, facilitating the gang’s activities.
The importance of this final step can't be overstated. Identifying shared characteristics among fraudsters or even fraud techniques allows investigators to find—and hopefully fix—the failings that financial criminals exploit. In this case, pinpointing an institution as the root of the issue would give investigators a huge head start in eliminating a huge financial crime issue, whether the cause ends up being unintentional gaps in a bank's KYC program, intentional misconduct within an institution, or something else. This is the real value of building out fully contextualized stories from available data.
Context is king
The results we presented to the finance professionals assembled at the ACAMS conference were a picture-perfect demonstration of how a versatile, data-driven approach is critical to comprehensive FRAML identification: today more than ever, systems need to be increasingly flexible and dynamic in order to shed light on increasingly sophisticated bad actors hiding in the shadows. When flexibility and dynamism become most valuable, however, are when suspicious activities are put in a broader context, allowing the stories of how money moves to come to light not just quickly, but fully. This is how financial companies can improve their investigations, how even the cleverest financial criminals can be brought to justice, and how innocent consumers will be protected from falling victim to the measures meant to protect them. This is how Resistant AI fights financial crime.
Fraud awareness, examples, and lessons
Learn more about fraud in specific industries, best practices, and targeted documents.
View all
In our last article, we teased that Fakedocshop, a popular document template farm running on subscriptions, has ...

Fake New York business licenses are risky in 2026. Whether it’s to provide jurisdictional privileges, or renew the ...

When we think about APP fraud, our hearts go out to the victims. But in 2026, banks in the UK are shouldering a ...

If you've seen as many template farm websites as we have, things start to blur. Hundreds of sites are selling ...

Key takeaways AI receipt generators are available. A simple Google search can reveal the top tools on the market. ...

Whether it’s a forged medical diploma or a suspicious Australian degree used for a Hong Kong visa application, ...